
Inleiding
De laatste jaren volg ik met veel aandacht de ontwikkelingen met betrekking tot GDPR en de publieke opinie over privacy en persoonlijke data. Zowel vakmatig, de impact op het advertising eco-systeem, als uit persoonlijke interesse als consument. Jaren geleden sprak ik al met grote bedrijven uit telecom, retail, publishing en finance over hun wens om meer met hun data te doen. Om hier een verdienmodel omheen te ontwikkelen en hoe dit het best vorm te geven. Bij deze gesprekken voelden deze bedrijven zich duidelijk nog eigenaar van deze data, die immers op hun servers stond en door hen gegenereerd was. Het werd ook meteen duidelijk, afgaand op de negatieve reacties op de aankondiging van ING om transactie data te gaan verhandelen, dat consumenten dit niet zomaar accepteren. Dit voorval heeft veel ‘explore trajecten’ naar nieuwe data verdienmodellen in de la doen verdwijnen. Sterker: ándere partijen kunnen gaan nadenken over verdienmodellen op de data van deze bedrijven.
Persoonlijke data is eigendom van het individu
Alle persoonlijke consumentendata die opgeslagen is bij banken, uitgevers, streamingdiensten, tech partijen, telecom bedrijven, retailers, overheden, universiteiten en andere partijen zijn eigendom van de betreffende individuen. Deze partijen (bedrijven en overheden) moeten sinds de Europese GDPR wetgeving -AVG zoals deze in Nederland genoemd wordt- van kracht is, persoonlijke data ter beschikking kunnen stellen aan de rechtmatige eigenaar, als deze daar een verzoek voor doet. Dit betekent dat bedrijven hier hun systemen op moeten inrichten om hieraan te voldoen.
Veel data is op allerlei verschillende plekken opgeslagen, in ERP, CRM en andere systemen, dus het is een uitdaging voor bedrijven om deze data snel en efficient toegankelijk te maken. Daarnaast vragen nog niet veel consumenten hun data op, dus is er (nog) geen grote noodzaak om dit goed te automatiseren. Toch zou het, om verschillende redenen, goed zijn als hierop nu wel voorgesorteerd wordt. Ten eerste uiteraard vanuit de juridische noodzaak. De boetes voor het niet juist toepassen van de GDPR wetgeving zijn fors. Een groot bedrijfsrisico. Ten tweede zullen consumenten steeds bewuster worden van hun rechten en ontstaan er steeds meer diensten waarbij de data van consumenten waarde toevoegt. Een voorbeeld hiervan is Dyme, waarbij consumenten, na het uploaden van hun banktransacties, inzicht krijgen in hun huishoudboekje en bespaartips krijgen. Ten derde is er steeds meer tractie op het onderwerp in de markt, Zo zijn mediapartijen in Nederland aan het testen met ‘Personal Data Pods’ van Solid, om consumenten in staat te stellen om bijvoorbeeld recommendation engines slimmer te maken door deze te voeden met hun persoonlijke kijkgedrag over meerdere platforms.
Consumentenrecht
Consumenten hebben het recht om informatie te ontvangen over welke data er wordt opgeslagen en wat er met hun data gebeurt. Daarnaast hebben consumenten het recht op toegang tot de data. Dit moet op een eenvoudige, directe manier mogelijk worden gemaakt in een veilige omgeving. Waar het grote databestanden betreft moet de mogelijkheid geboden worden om een selectie te maken en aan te geven welke data op welke manier gedeeld moet worden.
Hierbij is het uiteraard belangrijk dat de identiteit goed gecontroleerd wordt voordat data gedeeld wordt. De data moet vervolgens meegenomen kunnen worden naar andere partijen, op een geautomatiseerde, gestructureerde, machine-readable, algemeen gebruikt en interoperable format. Dit is momenteel binnen de bancaire wereld geregeld door een door de EU opgelegde standaard om betaalgegevens van bankklanten gestructureerd toegankelijk te maken voor derden: PSD-2. Consumenten kunnen derden nu toegang geven tot hun betaalrekening als ze daar toestemming voor geven. Hierdoor ontstaan interessante nieuwe diensten, zoals het eerder genoemde Dyme. In alle andere branches is er nog geen standaard (denk aan retail loyalty programma’s, overheden, streamingdiensten, social media, medische instanties, enz.) maar de verwachting is dat dat snel gaat veranderen, hetzij geïnitieerd door branches zelf, hetzij gedwongen door de overheid.
DSAR requests experiment
Hoe gaan Nederlandse bedrijven nu om met de wetgeving en de rechten van consumenten om toegang te hebben tot hun data? Om hier inzicht in te krijgen heb ik een experiment uitgevoerd. Hierbij heb ik –over een periode van 1,5 jaar- mijn persoonlijke data opgevraagd bij verschillende partijen en gekeken hoe hierop gereageerd is. Zo’n verzoek om persoonlijke data wordt ook wel een Data Subject Access Request (DSAR) genoemd. Meerdere nationale en internationale partijen zijn hierbij gevraagd om toegang tot persoonlijke data en deze aan te leveren: Ziggo, Facebook, Google, AH, CBS, KPN, Apple, Netflix, Amazon, ING en Bol.com. Het proces is vervolgens vastgelegd waarbij gekeken is naar de snelheid, het aanvraagproces, identificatie procedure, beveiliging van de data, aanlevering, bestandsformaten, gebruikerservaring en hoe lang het duurt voordat de data wordt geleverd.
Resultaten
De resultaten zijn weergegeven en samengevat in bijgaande Infographic. Opvallend is dat een aantal grote Nederlandse bedrijven nog geen geautomatiseerd proces heeft neergezet om DSAR requests te behandelen. Soms was het ook flink zoeken op de websites van deze bedrijven naar een contactpersoon of mailadres waar het verzoek kon worden ingediend. Een aantal bedrijven reageerden ook verbaasd en vroegen om de reden waarom deze data werd opgevraagd. Blijkbaar zijn deze verzoeken nog schaars. Ook wordt in sommige gevallen eerst een zeer beknopte PDF geleverd en werd pas na aandringen en doorvragen de daadwerkelijke dataset in horten en stoten aangeleverd. Het leek in deze gevallen ook een handmatig proces, waarbij iemand uit verschillende systemen data in een Excel heeft gezet. Opvallend was dat het Centraal Bureau voor de Statistiek geen persoonlijke data levert. Dat werd als volgt uitgelegd:
“Ten aanzien van het inzagerecht geldt het volgende. In artikel 15 van de Avg is het inzagerecht van betrokkenen, wiens gegevens worden verwerkt, vastgelegd. Kort samengevat komt het erop neer dat u in beginsel het recht heeft om inzage te verkrijgen in uw persoonsgegevens en de wijze waarop, wanneer en voor welk doeleinden deze verwerkt zijn. In artikel 44 van de Uitvoeringswet AVG (UAVG) is echter onder voorwaarden vastgelegd dat de instelling die statistiek maakt (CBS) niet verplicht is het inzagerecht uit te oefenen. Van belang hierbij is dat het CBS de wettelijke taak heeft om statistisch onderzoek te verrichten voor beleid, praktijk en wetenschap alsmede het bevorderen van de statistische informatie voorziening. Uitsluitend in dit kader ontvangt CBS persoonsgegevens, zodat hij zijn wettelijke taken kan uitvoeren. Ik benadruk dat CBS nooit informatie publiceert waar herkenbare persoonsgegevens aan kunnen worden ontleend. Dat is specifiek bij wet bepaald en daar zien strikt beleid en strikte procedures op toe. Al met al komt CBS op grond van artikel 44 UAVG niet tegemoet aan uw verzoek tot inzage.”
Bovenstaande is dus iets waar overheden zich nog achter kunnen verschuilen en waar nog geen jurisprudentie over is. De grotere Amerikaanse tech partijen doen het opvallend goed. Zij zijn waarschijnlijk wijs geworden door de enorme boetes die zij in het recente verleden hebben moeten betalen en doordrongen van de ernst van de Europese wetgeving. Daarnaast hebben zij de technologische knowhow en infrastructuur om dit goed op te zetten. Doorgaans bieden zij meerdere bestandformaten, selectie mogelijkheden over welke periode de data aangeleverd moet worden, een API koppeling om een continue datastroom te ontvangen en een beveiligde persoonlijke omgeving waarin de data kan worden opgehaald.
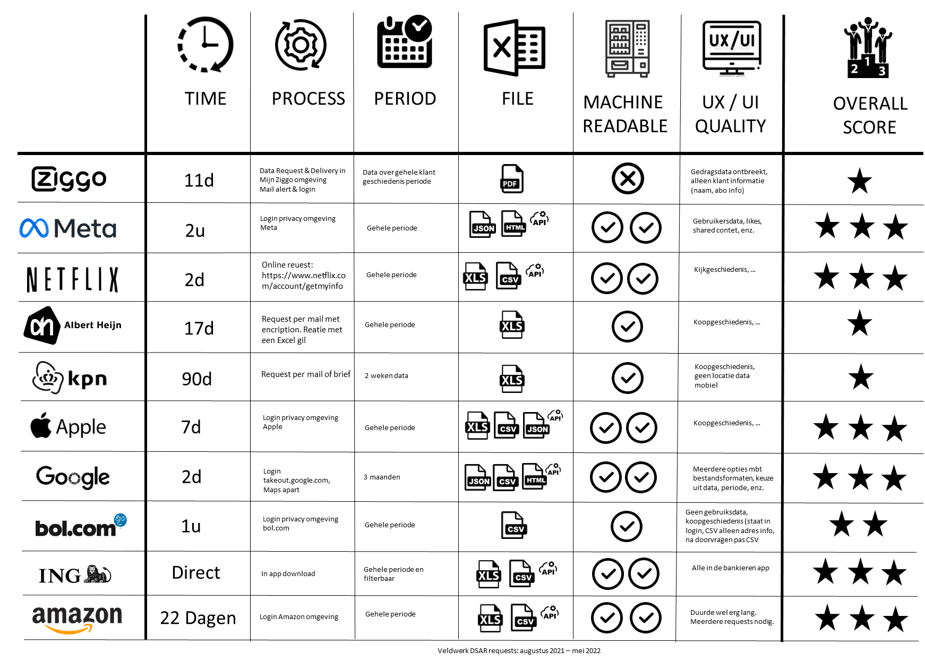
De beste Nederlandse partij in dit experiment is ING bank en de minste punten behaalt telecompartij Ziggo, mede omdat het vermoeden bestaat dat er meer data is (bijvoorbeeld verplaatsingsgedrag via de app en kijkgedrag) dan dat er geleverd wordt. Hierbij kunnen bedrijven ook zelf nog labelen wat wel en niet als persoonlijke data wordt gedefinieerd en aangeleverd. Een consument kan nu niet bewijzen dat er onvolledig geleverd wordt door bedrijven en instanties.
Nogmaals, dit was slechts een steekproef uit de bedrijven die persoonlijke data opslaan van Nederlanders. Naast de juridische eis dat persoonlijke data ontsloten en op verzoek aangeleverd moet worden is het ook voor de wetenschap en de ontwikkeling van AI belangrijk dat data gedemocratiseerd wordt. En dat consumenten toestemming kunnen geven om met hun data aan de slag te gaan. De derde Internet-laag die momenteel in de steigers staat (Tim Berners Lee startup Solid of een andere partij), gaat daar de technologische basis voor leggen. Consumenten kunnen dan op een eenvoudige manier hun (persoonlijke en niet-persoonlijke) data delen met universiteiten, onderzoekers en bedrijven voor doelen (en rewards) waar zij achter staan. Eerste stap is dat bedrijven hierop voorsorteren met hun datamanagement en data ontsluiting. Uit dit experiment blijkt dat veel bedrijven dit nog niet op orde hebben. Aan de slag dus!
